
Abstract
The Global Burden of Disease Study (GBD) began 30 years ago with the goal of providing timely, valid and relevant assessments of critical health outcomes. Over this period, the GBD has become progressively more granular. The latest iteration provides assessments of thousands of outcomes for diseases, injuries and risk factors in more than 200 countries and territories and at the subnational level in more than 20 countries. The GBD is now produced by an active collaboration of over 8,000 scientists and analysts from more than 150 countries. With each GBD iteration, the data, data processing and methods used for data synthesis have evolved, with the goal of enhancing transparency and comparability of measurements and communicating various sources of uncertainty. The GBD has many limitations, but it remains a dynamic, iterative and rigorous attempt to provide meaningful health measurement to a wide range of stakeholders.
Similar content being viewed by others

Main
The Global Burden of Disease Study (GBD) is a systematic, scientific effort to quantify the magnitude of all major diseases, risk factors and intermediate clinical outcomes in a highly standardized way, to allow for comparisons over time, across populations and between health problems. The first GBD began in 1991 and led to the first results being published in 1993, which documented for eight regions the burden of disease for 106 conditions and ten risk factors, broken down into five age groups for the year 1990. The GBD now provides estimates for each year from 1990 to the present for 371 diseases and injuries, as well as 3,499 clinical outcomes (sequelae) related to those diseases and injuries, for 204 countries and territories and for subnational units in more than 20 countries. The full time series produced in each round of the GBD is updated on an annual basis1,2,3,4,5, although the coronavirus disease 2019 (COVID-19) pandemic has delayed the release of the next GBD assessment. Since serialization in 2010, 1,842 publications on the GBD have appeared in the scientific literature.
Although there are many efforts in many countries to measure outcomes relating to single diseases or risks or groups of these, the GBD stands apart because of some core principles consistently applied over the last 30 years. Beginning in 1991, when the first GBD was undertaken as background work for the World Development Report 1993: Investing in Health6, the GBD was committed to the principles of best estimates, comprehensive accounting, comparable measurement, summary measures of fatal and non-fatal health outcomes and thoughtful and repeated assessment of face validity of findings. In this Perspective, we reflect on lessons learned from 30 years of the GBD. We begin by reviewing the core principles, and then we examine the universe of data for tracking health, the ongoing evolution of the statistical methods to support the GBD, the history of the broader GBD collaboration and some key future directions for the effort.
Core principles
Best estimates
The GBD estimates each quantity of interest for every location. Even when data are highly inconsistent or there are no data for a disease or risk, a best estimate is produced along with our best estimate of uncertainty. The logic is that decisions have to be made, and a best estimate borrowing insight from where data are available is better than no estimate, provided that there is clarity around the level of uncertainty. All too often, ‘no data’ has been historically equated to ‘no problem’, biasing prioritization and agenda-setting toward diseases, injuries and risk factors for which data have been collected and/or advocacy groups exist. This commitment to best estimates has catalyzed a continuous search for better global data (volume, veracity, variety and timeliness are all prized) as well as continuous efforts for better statistical estimation methods to deal with missing data and conflicting data that inevitably remain. It also sharply distinguishes the GBD from many government or intergovernmental efforts both in health and in other social sectors and remains the most frequently misunderstood part of the GBD.
Comprehensive accounting
This second core principle applies across diseases, injuries and risks. Comparable information on the magnitude of different health problems provides an objective framework to help establish health priorities and, importantly, can also provide important insights into what topics may be neglected. In the 1990s, the GBD finding that the burden of mental health disorders was substantial relative to infectious diseases, heart disease and cancer prompted the World Health Organization (WHO) and many countries to devote more policy attention to these neglected problems7. A high-level view of the comparative magnitude of health problems has also highlighted the rapidity of the epidemiological transition in many middle-income (and former low-income) countries where the profile of burden has shifted from communicable, maternal, neonatal and nutritional deficiencies to non-communicable diseases and injuries2. In more recent years, this principle has had increasing benefits as this comprehensive estimation has become a somewhat unique resource, in allowing the holistic forecasting of population health effects in an ever more rapidly changing and challenged world.
Comparability of measurement
Comprehensive accounting requires a focus on comparability of measurement. Many authors and statistical authorities have argued that the most important comparisons are within a country; but, from the beginning of the GBD, we have seen the value of emphasizing comparability over time and across place. Decision-makers who use the GBD results are drawn to understanding why their community may have a larger or smaller burden from a condition or, even more importantly, faster or slower rates of decline or increase in a disease, injury or risk factor, compared to other communities or regions. Meaningful comparisons are at the heart of efforts such as the Millennium Development Goals monitoring and the Sustainable Development Goals monitoring. But comparisons of levels or trends puts a very high premium on the comparability of measurement. Comparability of measurement requires the units of measurement to mean the same thing for an outcome at any point in time and in any location. This commitment in the GBD to comparability is part of the reason that each release of the GBD recomputes the entire historical time series for a disease, injury or risk factor so that changes in case definitions, historical datasets and methods do not lead to spurious comparisons with past assessments. This is another area of frequent misunderstanding, and communicating the drivers of change—from new data (contemporary and historical gap filling) and epidemiological insights to superior statistical methods and computing power—remains critically important in underscoring the value of gradual and iterative improvement of the GBD.
Morbidity and disability
Throughout the three decades of the GBD, we have striven to expand the traditional focus of global health on death or premature mortality to also encompass outcomes related to morbidity and disability. In addition to quantifying the incidence and prevalence of major clinical sequelae for each disease and injury, summary measures of fatal and non-fatal health have been an integral part of the GBD since 1991. Two key summary measures were proposed and implemented: disability-adjusted life years, and healthy life expectancy1,2. Disability-adjusted life years are the sum of years of life lost due to premature mortality plus years lived with disability. The latter has been estimated since GBD 2010 as the sum of the prevalence of each clinical sequela multiplied by the public’s view of how much health loss is associated with each health state. The latter has been evaluated through a range of national sample surveys spanning low-income, middle-income and high-income countries2. Summary measures that reflect the full range of health outcomes have highlighted the importance of a holistic assessment of health when determining priorities and have enabled a better understanding of how increased longevity can also be a mixed dividend if a large proportion of that time is spent struggling with ill health.
Face validity
The final core principle is the commitment to careful evaluation of face validity. Too often, health measurement has been seen as a mechanical task: the analysis of data using some statistical procedure, the results from which are released regardless of face validity. By repeatedly estimating over the three decades, we have learned that, when data and analysis yield results that make little sense compared with local or global expert knowledge, there are often unrecognized biases at work. We are aided in identifying potential face validity challenges by having so many active participants in the study who can help verify the ‘ground truth’ of results. But, just as importantly, we are always trying to triangulate on results and look for anomalies in the relationship between different quantities of interest. Modeling incidence, prevalence, remission, excess mortality and cause-specific mortality means that we can examine patterns in factors such as excess mortality to identify when data errors may be leading to implausible findings. Internal consistency is another important dimension of face validity: for example, we require the estimates of cause-specific mortality to sum to estimates of all-cause mortality. Estimates of anemia by cause are required to sum to estimates of anemia from all causes. The GBD is certainly not the first group to focus on face validity; in fact, this tradition has always been very strong in applied demographic analyses. Over the 30 years of the GBD, as the collaboration has grown and the scope of the GBD has increased, we have made an increasingly robust effort to obtain wide-ranging feedback on the processing and results of each GBD estimation. Across the GBD collaboration, there is wide expertise in each disease, injury and risk factor, which aids in sense-making. The collaboration is overseen by a council made up of experts across many disciplines and from all regions of the world. In addition, an independent group, the Independent Advisory Committee for the Global Burden of Disease, meets every 6 months to review the work and make recommendations for improvement. Close collaboration with WHO Headquarters and WHO Regional Offices also provides structured opportunities for input. These efforts are all in addition to the normal rigors of peer review for the many articles published from each round of the GBD. It is an indication of empirical integrity that, as our understanding of population health increases, our assumptions of the past should always be available for challenge, improvement and change.
The dataverse
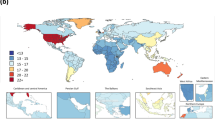
Critical to any systematic assessment of descriptive epidemiology is identifying, obtaining and evaluating the universe of data on any outcome (Fig. 1). Well-developed methods enshrined in guidelines such as PRISMA8 have established approaches for dealing with the published literature; these approaches have become part of the GBD approach as well. But many more data are not published than are published in the peer-reviewed literature; the role of administrative data in the GBD grows with each cycle. Many governments release vital statistics on an annual basis and, as we have seen during the COVID-19 pandemic, even on a daily basis. Survey programs such as the Demographic and Health Surveys (DHS; https://dhsprogram.com) capture a wide range of critical variables, as do other national survey programs, such as the US National Health and Nutrition Examination Survey. Clinical informatics, including International Classification of Disease (ICD)-coded data on visits, claims data and electronic health records data, are examples of rich data sources that are not in the peer-reviewed literature, and, for many GBD outcomes, the preponderance of data come from these sources. Some of these data sources are routinely released into the public domain, such as the DHS surveys or many countries’ vital statistics. For many other sources, however, access must be negotiated with data holders. The GBD collaboration, with widespread participation in more than 150 countries, has greatly facilitated negotiating access to data. Nonetheless, many data sources in existence are not widely available. Some important data collection platforms, such as the WHO-supported STEPS surveys, remain solely available to the WHO to analyze or to select research groups to be given access to this resource9. There are many other examples of datasets effectively held as a private good by individuals in government, international agencies or academia. Datasets are often viewed as a source of power or advantage that can be used to the data holder’s advantage, creating a powerful disincentive to data sharing; frequently, these data holders use protection of privacy as the excuse for not sharing. These claims, however, fall apart when data are selectively shared with some groups and not others.

GBD 2021 data sources by data type. a, Total number of GBD 2021 sources by location. b, Total number of GBD 2021 DHS sources by location. c, Total number of GBD 2021 Vital Registration Survey source-years by location.
The Institute for Health Metrics and Evaluation (IHME), the coordinating center for the GBD, hosts an online data catalog for all data sources used in the GBD. The GBD never imposes any additional data-sharing constraints on data shared, but neither does it break any contractual specifications negotiated on sharing. Rather, we continually encourage data sharing with a view to increasing transparency and reproducibility while protecting the rights of individuals covered by datasets. We share 113,297 sources of data and direct over 1,000 inquiries per annum to data librarians in the event that we do not have the rights to share. Since the start of the GBD, the global health database has grown from 13,688 to 150,037 sources and is a continued and often unseen part of the energy and investment of the GBD enterprise and staff, now ingesting some 14,369 new information sources each year.
Some expected that the GBD would fail to gain access to sufficient data from a range of countries to undertake robust estimation for a broad set of causes. However, two positive factors have led to considerable success in negotiating access to data. First, thousands of collaborators who are authors of GBD scientific publications have created a strong sense of inclusion and co-ownership of the results. We estimate that over 10,000 authors have contributed across the 30 years of the GBD. Second, many governments have shared data because they have appreciated the longevity of the GBD and seek more accurate future GBD assessments, particularly at the subnational level. Although it is difficult to document systematically, we are aware of many governments—including China, Chile, Costa Rica, Ethiopia, Brazil, Indonesia, India, Japan, Nepal, Nigeria, Norway, New Zealand, Pakistan, Poland and the United Kingdom—that have fully used GBD findings in their national planning. A very recent example comes from a new law that mandates health insurance coverage and creates a vulnerable group fund for the 83 million poorest Nigerians, which was enacted by President Muhammadu Buhari10 based on specific recommendations of the Lancet Nigeria Commission (which used GBD estimates extensively)11. In effect, the GBD has provided a stable and trusted service to many data holders, motivating them to engage, share data, cogently critique and ultimately own outcomes on which to inform policy.
Data evaluation and processing
A critical dimension of the GBD is the detailed efforts to evaluate the hundreds of thousands of data sources used in each analysis. For example, making sense of cause of death data involves careful assessment of surveys, censuses, cohort studies and administrative data. Data on causes of death from vital registration sources are mapped across different versions of the ICD and various national variations of it. Deaths assigned to causes that cannot be true underlying causes of death or that are unspecified are reassigned to likely underlying causes of death using statistical algorithms developed over the three decades of the GBD. To help communicate to users of the cause of death results, the data for each location are given a star rating on a one-star to five-star scale, reflecting the completeness of vital registration, the fraction of deaths that are assigned to unspecified causes and the detail of the ICD lists used for each source. The star ratings and the supporting detailed analysis of strengths and weaknesses of cause of death data are released along with the GBD results with each cycle of the GBD analysis. Evaluation of the quality of data and processing of that data to enhance comparability requires examination of response rates, geographic coverage for surveys or completeness of enumeration for censuses. For relative risk of an outcome after exposure to a risk factor, data from cohort studies and trials are evaluated on multiple dimensions, including risk of confounding, generalizability, reporting bias and publication bias. As new issues in descriptive epidemiology are identified in the literature, whether for a single source or for classes of sources, the GBD attempts to address these potential sources of bias in the next cycle.
Scope of GBD results
Given the comprehensive approach of the GBD, including production of a revised time series from 1990 for all outcomes and results for demographic estimates from 1950 to present, the scope of results is large. Figure 2 shows how the scope of the GBD in terms of the quantities of interest has grown through each revision. All of these results are available online (https://vizhub.healthdata.org/gbd-results/) and can be queried through interactive online tools, the most important of which is GBD Compare (https://vizhub.healthdata.org/gbd-compare/).

Change in total estimation categories (for example, combined number of estimation years, locations, age groups, risks, causes, injuries and impairments) included in the GBD.
Statistical methods fit for purpose
The GBD has stimulated the development of many analytical and statistical methods to tackle the common problems in global descriptive epidemiology12,13,14,15,16,17,18. Seven issues create unique challenges: sparse or missing data for an outcome in a location; conflicting data (with non-overlapping confidence intervals) for the same outcome in the same place; heterogeneous case definitions, assays or instruments; non-sampling error; administrative data that exclude certain groups; limited predictive power of available covariates for an outcome; and the need to deal with anomalous studies or data points. With the drive to bring GBD estimation to a much more detailed level—such as the US National Institutes of Health–funded effort to estimate the burden of disease by county and race/ethnicity group or the estimation of burden for upper tier local authorities in England—small-number (sample-size) issues have become increasingly important. Although these problems have existed throughout the 30 years of the GBD, the methods used to address them have continuously evolved. One of the hallmarks of the GBD effort has been to constantly innovate to build stronger tools to address these challenges.
Since GBD 2010 (refs. 13,14,15,16,17,19,20), we have addressed the main estimation challenges by building statistical analytical tools that directly address the technical challenges we have identified. For example, the wide array of case definitions, assays and instruments that may exist across datasets has been addressed through the analysis of cross-walking—namely, the statistical relationship among matched measurements using different case definitions, assays or instruments. Once derived, this statistical cross-walk is used to pre-process data that use alternative measurement approaches so that they become equivalent to the reference approach. For example, the prevalence of schistosomiasis due to Schistosoma mansoni measured using alternative methods, such as circulating cathodic antigen detection or formol-ether concentration, is adjusted to be equivalent to the reference definition of prevalence measured using three standard Kato–Katz stool smears. Another example is the development of Cause of Death Ensemble modeling (CODEm) to estimate cause of death rates by age, sex, year and location using an ensemble modeling strategy21. Wherever possible, the design of these GBD statistical approaches has involved holding out a fraction of the data and evaluating the performance of different methods by comparing predictions of those methods against the data that have been held out from the analysis (known as out-of-sample predictive validity testing) rather than cherished techniques, statistics and methods.
For some outcomes, such as major depression, substance abuse or uterine fibroids, available covariates have limited predictive power; therefore, the main analytical methods used in the GBD also use the pattern of unexplained variation from statistical models over space and time to improve estimation. These residuals tend to be correlated over space and time, and a wide array of methods that have long been used in geospatial analyses can be used to capture these patterns and include them in estimation. Because of this often-high correlation of residuals over space and across time, better ways (including ensemble methods) to capture these relationships are an area of active research by the GBD.
A particularly thorny problem in global descriptive epidemiology is the identification of anomalous studies or data points that should be excluded from the analysis. Statistically significant order-of-magnitude differences for disease incidence or prevalence for the same outcome in the same location and year are not unusual; both findings are highly unlikely to be true. Perhaps more common is a single finding in a location that is substantially higher than past measurements in the same location or adjacent locations. In general, disease and risk factor rates are quite correlated across locations, making markedly different rates a potential indicator of data anomalies. But a principled basis for excluding studies, or outliering, is often controversial. Different groups of experts may disagree; in fact, major differences in descriptive epidemiology can often be traced to decisions on data processing or outliering22,23,24. In the development of the Guidelines on Accurate and Transparent Health Estimates Reporting (GATHER), one criterion was to list all the data outliered and the reasons for outliering25. In the work on estimating relative risk functions for a risk–outcome pair in the Comparative Risk Assessment part of the GBD, automated outliering using a method called trimming has been used as a standardized tool18,26. Wider use of trimming, which is computationally costly, in other areas of GBD estimation is currently being researched.
GBD collaboration
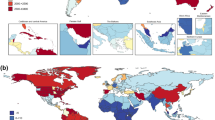
The original publications on the GBD in 1995 (ref. 27) and 1996 (refs. 28,29,30,31) had two authors: one from academia and one from the WHO. In the last 100 GBD publications, the average number of authors has been 242. The reason for the considerably more inclusive approach has been the growth of the formal GBD collaboration. Figure 3 shows a map of current GBD collaborators in 157 countries and territories. Some 45% of GBD collaborators are from low- and middle-income countries. Almost a third, 32%, identify as female. The growth of the collaboration has required careful cultivation with a dedicated team at the IHME devoted to communicating, sustaining and cultivating work. Note that the particularly frequent groupings of collaborators often reflect nations in which direct shared work on metrics has been prioritized (for example, India, Brazil and Ethiopia, among others).

Distribution of GBD Collaborator Network members for GBD 2021.
In some countries, collaborators have organized themselves into various national committees or expert groups. The Indian burden of disease collaboration, for example, jointly sponsored by the Indian Council of Medical Research, the Public Health Foundation of India and the IHME, has published 15 papers and reports that have had considerable influence on Indian national health policy32,33,34. Another example is the network of 158 collaborators in Brazil from a wide variety of government and university institutions that has recently published a series of papers on subnational public health issues of concern35. A third example is the 1,005 collaborators in Ethiopia, including the Minister of Health, who recently published their first subnational assessment of burden in Ethiopia36. As GBD matures, so do the various working models of our collaborative endeavors, striving always for ever-increasing autonomy at the national level.
Sustaining a collaborative approach to large-scale projects creates many challenges. A typical GBD analysis, such as risk factors for cancer, generates more than 8,300 comments from 1,222 collaborators in the drafting stage. Working through the detailed comments from so many contributors makes group writing more challenging but has clearly increased the quality of the analysis and the broader ownership of the results once published. Although costly in terms of person-time, the GBD approach to actively promoting participation in the analysis and writing up of results yields benefits, and we hope this will be part of sustaining its future.
Limitations
A study of the scope and ambition of the GBD has many limitations. First and foremost, there remain huge data lacunae for important health outcomes. In countries with incomplete vital registration with medical certification of causes of death, verbal autopsy data are often the only source available, but verbal autopsy data have many limitations. Some countries have not had a census in decades, so even the number of people in a country is uncertain. Second, users of the GBD results may not understand the true uncertainties in the measurements, although the GBD uses multiple methods to try to communicate the strength of data or evidence underlying a finding. We report star ratings on the quality and completeness of cause of death data; we provide uncertainty intervals for every measurement; and we map the raw data availability and compute data availability scores. In the forthcoming GBD assessment, we have introduced a star rating for the risk of confounding for risk–outcome relationships. Nevertheless, it is possible that the uncertainties related to measurements may be overlooked or misunderstood in some cases. Third, data processing steps (such as correcting cause of death data for deaths assigned to vague or unspecified causes) can have profound effects on the results. There is substantial debate and discussion across the GBD collaboration on some aspects of data processing. But there is, in general, less discussion in the literature on these processing steps than on the universe of data or the statistical methods used for data synthesis. Fourth, the large array of different data sources with many potential sources of bias, combined with missing data for location-years, makes the GBD analysis for a single outcome complex. Building in requirements for internal consistency across outcomes, such as cause-specific mortality summing to all-cause mortality, greatly expands complexity. Some users assume that transparency of data, data processing and statistical analysis should equate to simplicity. Unfortunately, this is not the case. Any substantive attempt at dealing with the diversity of data sources and the nuances of potential biases will inevitably lead to more complexity than some users would like; but artificially simplifying analyses by choosing to ignore real issues of bias could lead to misleading results. Fifth, for risk exposure to health outcome relationships, relative risks are assumed in most cases to be generalizable across populations. This is driven by two realities. On the one hand, much more cohort data are available from high-income countries; but for the few risk–outcome relationships that are based on more diverse cohorts, there has not been convincing evidence of large variation in relative risk functions related to geography. As more cohort data are hopefully collected from around the world, the GBD will have to continuously assess whether relative risk functions do vary by location. Sixth, at times, the data suggest patterns of disease and exposure or relative risk functions for exposure and outcome that vary from expert consensus. In the GBD, we are strongly committed to a rules-based approach to evidence synthesis. This can lead to situations where the GBD findings may diverge from other assessments that place more weight on expert views. Some users could be confused by this disagreement. We think that such disagreements (when face validity is established) should be a catalyst for further debate and research that may clarify the situation for a given disease, risk or relationship.
Future directions
Across the GBD collaboration, the GBD is moving in multiple directions. The common theme for these innovations is to make the GBD results more relevant to decision-making and more transparent and reliable to all users.
We have learned through experience that GBD analyses are more likely to be used for policy formulation and positive change when there is strong local ownership and expertise. A key direction for the GBD in the next decades will be to create more groups of collaborators or institutions to undertake vigorous GBD analyses, such as those that have evolved in India and Brazil. This effort will require three factors coming together: GBD analytical tools that can be run without access to a high-performance computation cluster or, alternatively, cloud-based tools; capacity building in data science applied to health and, in particular, the GBD; and local institutional support for local groups of GBD collaborators. This push toward decentralizing the GBD will need to be undertaken in a way that will preserve the core GBD principles (with which we started), particularly comprehensiveness, comparability and best estimates. Making every effort to continue to democratize the input data and results will also be necessary to achieve this vision.
The original GBD 1990 analysis included forecasts to 2020 (ref. 28) using very simple methods. Another iteration of GBD forecasts was published using the same methods in 2004 (ref. 37). In 2017, a new forecasting approach was published, and this approach has also been used to forecast population growth to 2100 (ref. 5). There is considerable demand from many policymakers for forecasts of what is likely to occur and alternative trajectories given the achievement of specific targets or the adoption of specific policies. The Bill & Melinda Gates Foundationʼs Goalkeepers Report38 includes these forecast scenarios each year for a set of health-related Sustainable Development Goals. In the future, forecasts of the entire GBD and a set of policy-related scenarios will be released with each GBD cycle, and we expect many topic-specific and country-specific forecasting and scenario analyses. As noted, these extensions can build on the core principle of comprehensive accounting. In addition, we find that these new analytical forays (higher spatial resolution, refined age groupings or forecasting) challenge our methodological assumptions and have often led to enhancement, reform and always better understanding of the population health impact of the epidemiological processes estimated and described.
To date, estimates of the GBD have been developed for administrative level 1 (first administrative subdivision after country, often states or provinces) for 22 countries. Even more detailed estimates have been generated for upper tier local authorities in England for four rounds of the GBD; these fine-grained estimates have been extensively used by Public Health England (formerly the Office for Health Improvement and Disparities) for planning and communication39,40,41. More recently, research is underway on the burden of disease for US counties disaggregated by race and ethnicity. Other countries are looking into administrative level 2 (often at the level of counties or districts) estimation of the burden of disease. The demand for subnational assessments is strong, and more general methodological innovation is needed to make such estimation easier and expand the number of countries that are evaluated at this level.
To further enhance the transparency and interpretation of evidence on risk–outcome relationships, we have developed a new approach called the burden of proof risk function. The idea is to characterize the risk–outcome risk function that is closest to no relationship and that is consistent with the available evidence, taking into account between-study heterogeneity18. The burden of proof risk function will then be used to generate a star rating for risk–outcome relationships on a one-star to five-star scale. The stars can help users recognize where a risk–outcome relationship is likely or unlikely to be affected by the publication of future studies. Although we cannot avoid new studies changing our understanding of risk–outcome relationships, we can identify where such changes are more likely in the future.
The COVID-19 pandemic has highlighted the value of timely information on the magnitude of the pandemic on a day-to-day basis and the policy relevance of short-term to mid-term forecasts. Traditionally, the GBD has analyzed health data on an annual basis. However, as part of the IHME work on tracking the pandemic and modeling the future, we have analyzed daily and weekly data, leading to studies on excess mortality, past infections and model projections42,43,44,45,46. A key question that remains open is the extent to which, under the GBD aegis, we should seek to track data and estimate outcomes that change rapidly in a more frequent timeframe than annual. Many causes follow a characteristic seasonal pattern that can be estimated from available daily or weekly data, such as the increases in cardiovascular diseases seen in winter months in temperate climates. The expected seasonal pattern could allow for estimation of weekly patterns of burden that would be supplemented with real-time data for diseases and injuries—such as epidemic malaria, dengue or war—that can vary much more than on a typical seasonal pattern. Moving toward real-time GBD analysis would fill a critical need, but this has considerable infrastructure and analytical implications.
Conclusion
The GBD has flourished over the last 30 years fundamentally because it has filled a critical need in global health. We confidently predict that the need for timely, relevant and valid health information will not dissipate in the future as population health responds to a plethora of influences. Demands from decision-makers for timely information and translating that information into policy-relevant what-if scenarios will likely increase as decision-makers face increasingly complex choices for health systems and public health. We hope that the GBD will continue for another 30 years and be part of documenting our very human journey.
References
GBD 2019 Demographics Collaborators. Global age-sex-specific fertility, mortality, healthy life expectancy (HALE), and population estimates in 204 countries and territories, 1950–2019: a comprehensive demographic analysis for the Global Burden of Disease Study 2019. Lancet 396, 1160–1203 (2020).
GBD 2019 Diseases and Injuries Collaborators. Global burden of 369 diseases and injuries in 204 countries and territories, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet 396, 1204–1222 (2020).
GBD 2019 Risk Factors Collaborators. Global burden of 87 risk factors in 204 countries and territories, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet 396, 1223–1249 (2020).
GBD 2019 Universal Health Coverage Collaborators. Measuring universal health coverage based on an index of effective coverage of health services in 204 countries and territories, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet 396, 1250–1284 (2020).
Vollset, S. E. et al. Fertility, mortality, migration, and population scenarios for 195 countries and territories from 2017 to 2100: a forecasting analysis for the Global Burden of Disease Study. Lancet 396, 1285–1306 (2020).
World Bank. World Development Report 1993: Investing in Health https://openknowledge.worldbank.org/handle/10986/5976 (Oxford University Press, 1993).
Whiteford, H., Ferrari, A. & Degenhardt, L. Global burden of disease studies: implications for mental and substance use disorders. Health Aff. 35, 1114–1120 (2016).
Page, M. J. et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. Br. Med. J. 372, n71 (2021).
World Health Organization. The WHO STEPwise approach to noncommunicable disease risk factor surveillance. https://www.who.int/teams/noncommunicable-diseases/surveillance/systems-tools/steps/manuals (2020).
Ogundele, B. Buhari signs National Health Insurance Authority Bill into law. The Nation Newspaper https://thenationonlineng.net/buhari-signs-national-health-insurance-authority-bill-into-law/ (2022).
Abubakar, I. et al. The Lancet Nigeria Commission: investing in health and the future of the nation. Lancet 399, 1155–1200 (2022).
Flaxman, A., Vos, T. & Murray, C. J. An Integrative Metaregression Framework for Descriptive Epidemiology (University of Washington Press, 2015).
Lim, S. S. et al. A comparative risk assessment of burden of disease and injury attributable to 67 risk factors and risk factor clusters in 21 regions, 1990–2010: a systematic analysis for the Global Burden of Disease Study 2010. Lancet 380, 2224–2260 (2012).
Lozano, R. et al. Global and regional mortality from 235 causes of death for 20 age groups in 1990 and 2010: a systematic analysis for the Global Burden of Disease Study 2010. Lancet 380, 2095–2128 (2012).
Salomon, J. A. et al. Healthy life expectancy for 187 countries, 1990–2010: a systematic analysis for the Global Burden Disease Study 2010. Lancet 380, 2144–2162 (2012).
Murray, C. J. et al. Disability-adjusted life years (DALYs) for 291 diseases and injuries in 21 regions, 1990–2010: a systematic analysis for the Global Burden of Disease Study 2010. Lancet 380, 2197–2223 (2012).
Vos, T. et al. Years lived with disability (YLDs) for 1160 sequelae of 289 diseases and injuries 1990–2010: a systematic analysis for the Global Burden of Disease Study 2010. Lancet 380, 2163–2196 (2012).
Zheng, P. et al. The Burden of Proof studies: assessing the evidence of risk. Nat. Med. (in the press).
Salomon, J. A. et al. Common values in assessing health outcomes from disease and injury: disability weights measurement study for the Global Burden of Disease Study 2010. Lancet 380, 2129–2143 (2012).
Wang, H. et al. Age-specific and sex-specific mortality in 187 countries, 1970–2010: a systematic analysis for the Global Burden of Disease Study 2010. Lancet 380, 2071–2094 (2012).
Foreman, K. J., Lozano, R., Lopez, A. D. & Murray, C. J. Modeling causes of death: an integrated approach using CODEm. Popul. Health Metr. 10, 1 (2012).
Kassebaum, N. J., Lopez, A. D., Murray, C. J. L. & Lozano, R. A comparison of maternal mortality estimates from GBD 2013 and WHO. Lancet 384, 2209–2210 (2014).
Alkema, L. et al. Global, regional, and national levels and trends in maternal mortality between 1990 and 2015, with scenario-based projections to 2030: a systematic analysis by the UN Maternal Mortality Estimation Inter-Agency Group. Lancet 387, 462–474 (2016).
Kassebaum, N. J. et al. Global, regional, and national levels of maternal mortality, 1990–2015: a systematic analysis for the Global Burden of Disease Study 2015. Lancet 388, 1775–1812 (2016).
Stevens, G. A. et al. Guidelines for accurate and transparent health estimates reporting: the GATHER statement. PLoS Med. 13, e1002056 (2016).
Zheng, P., Barber, R., Sorensen, R. J., Murray, C. J. & Aravkin, A. Y. Trimmed constrained mixed effects models: formulations and algorithms. J. Comput. Graph. Stat. 30, 544–556 (2021).
Murray, C. J., Lopez, A. D. & Jamison, D. T. The global burden of disease in 1990: summary results, sensitivity analysis and future directions. Bull. World Health Organ. 72, 495 (1994).
Murray, C. J. & Lopez, A. D. Alternative projections of mortality and disability by cause 1990–2020: Global Burden of Disease Study. Lancet 349, 1498–1504 (1997).
Murray, C. J. & Lopez, A. D. Global mortality, disability, and the contribution of risk factors: Global Burden of Disease Study. Lancet 349, 1436–1442 (1997).
Murray, C. J. & Lopez, A. D. Mortality by cause for eight regions of the world: Global Burden of Disease Study. Lancet 349, 1269–1276 (1997).
Murray, C. J. & Lopez, A. D. Regional patterns of disability-free life expectancy and disability-adjusted life expectancy: Global Burden of Disease Study. Lancet 349, 1347–1352 (1997).
Dandona, L. et al. Nations within a nation: variations in epidemiological transition across the states of India, 1990–2016 in the Global Burden of Disease Study. Lancet 390, 2437–2460 (2017).
Dandona, R. et al. Subnational mapping of under-5 and neonatal mortality trends in India: the global burden of disease study 2000–17. Lancet 395, 1640–1658 (2020).
Pandey, A. et al. Health and economic impact of air pollution in the states of India: the Global Burden of Disease Study 2019. Lancet Planet. Health 5, e25–e38 (2021).
Malta, D. C. et al. The GBD Brazil network: better information for health policy decision-making in Brazil. Popul. Health Metr. 18, 23 (2020).
Misganaw, A. et al. Progress in health among regions of Ethiopia, 1990–2019: a subnational country analysis for the Global Burden of Disease Study 2019. Lancet 399, 1322–1335 (2022).
World Health Organization. The Global Burden of Disease: 2004 Update https://apps.who.int/iris/handle/10665/43942 (World Health Organization, 2008).
Bill & Melinda Gates Foundation. Goalkeepers Report https://www.gatesfoundation.org/goalkeepers/report/2021-report/ (2021).
UK Health Security Agency. GBD Compare: a new data tool for professionals. https://ukhsa.blog.gov.uk/2015/09/15/gbd-compare-a-new-data-tool-for-professionals/ (2015).
UK Health Security Agency. Health Profile for England: telling a story about our health. https://ukhsa.blog.gov.uk/2017/07/13/health-profile-for-england-telling-a-story-about-our-health/ (2017).
National Health Service. NHS Long Term Plan https://www.longtermplan.nhs.uk (2019).
Barber, R. M. et al. Estimating global, regional, and national daily and cumulative infections with SARS-CoV-2 through Nov 14, 2021: a statistical analysis. Lancet 399, 2351–2380 (2022).
Bollyky, T. J. et al. Pandemic preparedness and COVID-19: an exploratory analysis of infection and fatality rates, and contextual factors associated with preparedness in 177 countries, from Jan 1, 2020, to Sept 30, 2021. Lancet 399, 1489–1512 (2022).
Friedman, J. et al. Predictive performance of international COVID-19 mortality forecasting models. Nat. Commun. 12, 2609 (2021).
IHME COVID-19 Forecasting Team. Modeling COVID-19 scenarios for the United States. Nat. Med. 27, 94–105 (2020).
COVID-19 Excess Mortality Collaborators. Estimating excess mortality due to the COVID-19 pandemic: a systematic analysis of COVID-19-related mortality, 2020–21. Lancet 399, 1513–1536 (2022).
Acknowledgements
The growth of the GBD would not have been possible without many funders and supporters. The original GBD 1990 was primarily funded by the World Bank. The GBD based at the WHO from 1998 to 2003 was primarily possible because of the leadership and support of G. H. Brundtland, Director-General of the WHO. Since 2007, the GBD has been predominantly supported by the Bill & Melinda Gates Foundation. Other funders, such as the US National Institutes of Health, the UK Government, the Wellcome Trust, the New Zealand Government, the Norwegian Institute of Public Health and the Bloomberg Foundation, have also funded aspects or extensions of the GBD. The GBD collaboration would also like to thank R. Horton of The Lancet (whose vision and mission are closely aligned with our own) for a robust, critically constructive, enduring and enjoyable relationship.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Medicine thanks Charles Wiysonge and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Primary handling editor: Karen O’Leary, in collaboration with the Nature Medicine team.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Murray, C.J.L. The Global Burden of Disease Study at 30 years. Nat Med 28, 2019–2026 (2022). https://doi.org/10.1038/s41591-022-01990-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41591-022-01990-1
This article is cited by
-
A novel microglia-targeting strategy based on nanoparticle-mediated delivery of miR-26a-5p for long-lasting analgesia in chronic pain
Journal of Nanobiotechnology (2024)
-
The global, regional, and national burden of foreign bodies from 1990 to 2019: a systematic analysis of the global burden of disease study 2019
BMC Public Health (2024)
-
Living longer but in poor health: healthcare system responses to ageing populations in industrialised countries based on the Findings from the Global Burden of Disease Study 2019
BMC Public Health (2024)
-
Human resources for health and maternal mortality in Latin America and the Caribbean over the last three decades: a systemic-perspective reflections
International Journal for Equity in Health (2024)
-
Unacceptable use of substandard metrics in policy decisions which mandate large reductions in animal-source foods
npj Science of Food (2024)
