
Abstract
Potential benefits of precision medicine in cardiovascular disease (CVD) include more accurate phenotyping of individual patients with the same condition or presentation, using multiple clinical, imaging, molecular and other variables to guide diagnosis and treatment. An approach to realising this potential is the digital twin concept, whereby a virtual representation of a patient is constructed and receives real-time updates of a range of data variables in order to predict disease and optimise treatment selection for the real-life patient. We explored the term digital twin, its defining concepts, the challenges as an emerging field, and potentially important applications in CVD. A mapping review was undertaken using a systematic search of peer-reviewed literature. Industry-based participants and patent applications were identified through web-based sources. Searches of Compendex, EMBASE, Medline, ProQuest and Scopus databases yielded 88 papers related to cardiovascular conditions (28%, n = 25), non-cardiovascular conditions (41%, n = 36), and general aspects of the health digital twin (31%, n = 27). Fifteen companies with a commercial interest in health digital twin or simulation modelling had products focused on CVD. The patent search identified 18 applications from 11 applicants, of which 73% were companies and 27% were universities. Three applicants had cardiac-related inventions. For CVD, digital twin research within industry and academia is recent, interdisciplinary, and established globally. Overall, the applications were numerical simulation models, although precursor models exist for the real-time cyber-physical system characteristic of a true digital twin. Implementation challenges include ethical constraints and clinical barriers to the adoption of decision tools derived from artificial intelligence systems.
Similar content being viewed by others
Introduction
Cardiovascular disease (CVD) accounts for approximately one-third of all deaths globally and is the leading cause of disability-adjusted life years—the years lived with disability and years of life lost due to premature death1. Further, ischaemic heart disease (IHD) surpasses all other types of CVD as a cause of premature mortality, with access to, and adoption of, proven treatments being context-specific1. Attention to accurate and personalised risk assessment with tailored prevention treatments remains imperative. Currently, the risk of CVD and IHD is estimated using risk algorithms incorporating a small number of traditional risk factors. However, the substantial number of events occurring in individuals considered low risk by traditional algorithms2 and therapy resilience in those with risk factors3 highlight that many questions remain to optimise the effective use of preventative medicines, devices, and other therapies, from both health and economic perspectives.
Precision or personalised medicine is an evolving field worldwide and seeks to more accurately phenotype individual patients with the same condition or presentation, allowing tailored screening, diagnostics, and treatment4. Broad application of this concept has been facilitated by biological databases (such as the genome sequence)4 and use of bio- and other markers to stratify patients for more targeted therapy5. For years, ‘omics’ technologies have measured the activities of thousands of genes (transcriptomics), proteins (proteomics) or other molecular features simultaneously from a mixed collection of cells that generate high-dimensional complex data now termed ‘omics’ data, which advance understanding of the genotype-to-phenotype relationship6. The important premise is that genetic, microbial, proteomic, metabolic, clinical, and behavioural pathways characterise patients and their health4. Advanced computational techniques for large data sets may overcome this inherent variability between individuals for more precise clinical decision-making and choice of interventions4. An approach to realising the possibilities of precision medicine is the concept of the digital twin, whereby patient-specific therapy is based on using a virtual replica (the digital twin) to predict treatment outcome and to personalise prognosis for a patient (the real-life twin).
The health digital twin has its origins in the established industry practice of creating virtual models of physical systems or assets in the field to enable planning decisions, risk assessment, testing, and to anticipate maintenance7. Such feedback systems use new technologies, such as cloud computing, 5G communication networks, and prediction software, to enable a three-way convergence of the virtual model, the physical asset, and the real-time data acquisition and exchange between them7, which occurs via networking devices or sensors located in each twin8. Analytical algorithms extract, store, and integrate the data acquired from multiple sources to detect changes, trends and patterns, predict and diagnose failures, test alternative decisions, and overall optimise the performance of the real-life asset8. For this reason, twinning a process or an object offers cost and time-saving advantages over a model or simulation technique, and is routinely used in rail, road, and maritime transport, supply chain and plant operations, and civil engineering8,9. The manufacturing sector, for example, uses virtual twins of machinery or factory equipment8; also modern consumer products, such as smart cars9. An aircraft’s digital twin is critical to maintaining its structural and mechanical health over its lifetime8. At the healthcare facility and department level, testable scenarios based on real-time data inputs to a mirrored system are proposed to improve processes for staff allocation, visitor/patient flow, waiting time, equipment and other internal resource provision, emergency vehicle access and other service-related operations10.
In a similar way, and drawing also on origins within the human genome project4, an individual health digital twin receives a variety of data parameters to assist decision-making and predictive evaluations for a real-life patient. The overall construct is centred on a population-based databank comprising two key types of data. Firstly, deep phenotyping as sourced from electronic health records, biological, clinical, genetic, molecular, and imaging data. Secondly, the phenotyping of real-world data from the person’s environment, using mobile data sensors and wearable devices11. Assimilating these continuously acquired, multi-source data into clinically meaningful knowledge occurs through an automated, iterative process of data pre-processing, data mining, and data integration, that produces more useful information than is provided by any single data source8,12. In the cardiology context, these phenotypic data for a digital twin are analysed in a predictive framework comprising combined statistical and mechanistic modelling that enables reasoning in the twin13. From within the population-based databank, a real-life patient has a digital twin selected that represents the average characteristics of its closest cluster group11. The outcome of virtual interventions subsequently given to the real-life patient then feeds back into the databank to both modify the twin and add to the population data pool11. This dynamic loop is crucial to expanding the databank and ensuring its diverse physiological and demographic make-up. The paradigm draws on bioengineering and computer sciences to aggregate and analyse information from large patient cohorts.
Given the significant potential for the digital twin principle to empower CVD research, fuller understanding of its scope will be beneficial. Therefore, the aims of this review were to describe the research designated ‘digital twin’, with a focus on uses of the term and concept within CVD-related research; to summarise the key concepts; to identify the disciplines contributing to the field; and to describe the emerging challenges for the progress of digital twin research within the wider context of precision medicine.
Methods
Study design
We undertook a mapping review, modified to accommodate the broad questions of interest. A mapping review is exploratory in nature for the purpose of providing an overview about a topic, or determining the volume and nature of literature within a field14. Elements of systematic review methodology ensured a transparent and replicable search process, with adaptations in part because the focus was on the breadth of information and comprised heterogeneous research and non-research material. Hence, a systematic approach was taken to literature searching, but unlike a systematic review a mapping review excludes critical appraisal of the methodological quality of the literature and evidence synthesis15.
Database search strategy
Eligible papers from the peer-reviewed literature were identified from Compendex, EMBASE, Medline, ProQuest and Scopus databases. The search strategy was then adapted to each database. (Supplementary Note 1) Reference lists, including the results of citation chaining (a function within the Scopus database) were hand-searched to identify further publications or grey literature. Papers were included if they were published in English and if they were a research/experimental report, commentary, narrative, descriptive paper, or a book chapter. Letters, editorials, media articles and conference abstracts were excluded. No limitations were set for the publication date.
Other data sources
Names of companies were identified from article reference lists and internet searching. Websites were then reviewed to characterise the industry participants and their products in the CVD and non-CVD digital twin fields. Publicly available patent information was searched on the websites of the Canadian Intellectual Property Office (www.cipo.ic.gc.ca); the European Patent Office (www.epo.org/index.html); the United Kingdom Intellectual Property Office (www.gov.uk/government/organisations/intellectual-property-office); the United States Patent and Trademark Office (https://appft.uspto.gov/); and the World Intellectual Property Organization (https://patentscope.wipo.int/search/en/search.jsf).
Charting the data
The results that were charted (the step analogous to data extraction in a systematic review14,15) were limited to five fields: publication year; first author country; article type; the condition targeted and first author academic discipline. Additional information from the CVD-related papers was the purpose of the project; key concept or methodology; status of the digital twin model; and the databank used or created. Data from industry-related websites included the target condition(s); the digital twin product or databank; and availability of the product or development status. Patents were searched for the applicant; the title of the invention; and the application filing date. One author (GC) charted the data.
Data synthesis
Excel spreadsheets were used to chart the information from each source, and to organise the descriptive information. A narrative synthesis of the important underpinning concepts and challenging issues of digital twin science was based on an iterative scoping framework15 in which mapping key concepts and breadth of available information is emphasised over the depth of information from any one study.
Results
Type and recency of digital twin research
The search of five electronic databases yielded 88 papers from 83 authors. (Fig. 1) Papers were original research (48%); reviews (24%); narratives (8%); book chapters (7%); conference papers (2%); commentary or viewpoint (10%) and position papers (1%). Overall, the papers related to cardiovascular conditions (28%, n = 25), non-cardiovascular conditions (41%, n = 36), and general aspects of the health digital twin (31%, n = 27). (Supplementary Table 1) CVD was the subspecialty with the majority of papers (n = 25); subspecialties within the 36 non-CVD papers included diabetes (n = 3), critical care (n = 4), cancer (n = 5), hepatology (n = 3), and multiple sclerosis (n = 2). Most of the papers were published between 2016 and 2021, underscoring the recency of health-related digital twin research. Geographically, the first author locations were worldwide: Europe (n = 35), North America (n = 15), UK (n = 13), India (n = 6), China (n = 5), Russia (n = 4), Australia (n = 3), Turkey (n = 1), and Morocco (n = 1). First author affiliations were universities and research institutes (n = 67), hospital centres (n = 4), private facilities or companies (n = 10), or a combination of these settings. The breadth of interdisciplinary sciences that converge in the field was evident in the predominance of the non-clinical sciences, such as bioengineering, robotics and cybernetics, mathematics, biophysics, mechanics and high-performance computing, suggesting their crucial influence in driving health digital twin research.

Flowchart of the search process.
Health digital twin: key concepts
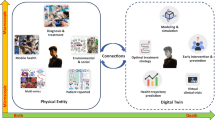
Regardless of the disease or condition in which digital twin research is applied, there are several shared, essential concepts (Box 1). First, the defining field of the computer sciences is artificial intelligence (AI). AI systems exploit processes that emulate human reasoning by using advances in four key fields, namely computational power, ‘big data’ processing, machine learning, and pattern recognition16,17. Second, the Internet of Things (IoT) refers to facilitating data exchange (including so-called ‘big data’) between different physical sources in a network8,18. IoT-enabled techniques for AI systems, combined with cloud computing, facilitate the creation of a digital profile of a real-world physical system8. Third, a digital twin requires bidirectional data exchange between the digital and physical twins on a continuous or at least periodic basis, which creates the characteristic cyber-physical system (CPS)8 (Fig. 2). The frequency of the data feed determines the relative passivity or activity of twin sub-types19. Fourth, whilst a digital twin can simulate a ‘what if’ scenario, the cumulative, real-time, real-world data exchange within the CPS gives the twin the further capacity for monitoring, diagnostics, and forecasting. This is enabled by what is known as closed-loop optimisation, whereby the constant synchronisation between the twins allows the virtual twin to quickly reconfigure as it adopts the properties of its physical twin, predicts problems, and tests potential solutions before deployment8. These more operational, intelligent elements differentiate a digital twin from a simulation-only model8,20.

Concept of a cyber-physical-system, enabled by the convergence and synchronisation of physical and virtual systems8.
The above capabilities—AI systems, IoT techniques and bidirectional data exchange—combine to surpass those of traditional data processing and improve the clinical utility of data-driven predictive and prognostic AI models21. For example, traditional data processing is typically associative, using epidemiological and statistical models based on structured, descriptive, retrospective data about a known population17,21. Such a data pool is more static than dynamic, usually accumulating steadily into local, centralised storage. Furthermore, data are often fragmented and isolated rather than merged with data from different sources, such as health records, wearable devices, and digital models8,18. In contrast, within the digital twin paradigm is the processing of high-dimensional, unstructured, decentralised data that accumulate prospectively and exponentially from multiple sources17,21, and contain (near) constant data flow from the environment, known as context-awareness7. Using a technique known as data fusion12, prescriptive- and predictive-type analyses of big data encompass so-called supervised and unsupervised machine-learning processes characterised, for example, by exploratory pattern recognition and use of physiologic, clinical, and social causal pathways in disease21. A subset of machine learning, known as deep learning and convolutional neural networks (Box 1), is posited to fundamentally change disease outcome prediction17,22. Taken together, the reasoning capability achievable with these data-driven technologies goes beyond both established processing with statistical techniques (such as logistic regression and decision trees17), and numerical, physics-based analyses as are used in haemodynamic models of coronary vessels23 or heart valve mechanics24.
Digital twin applications in cardiovascular disease
Research that used the term digital twin to describe models for addressing specific CVD-related clinical problems was detailed further (Table 1). Common to the methods used were simulation and modelling techniques from computing, bioengineering and mathematical sciences. The original research papers were best described as proof of concept and model validation; none were fully integrated into routine clinical practice, although seven were described as precursors to either an active or semi-active digital twin (Fig. 3). Nine discussion-type papers broadly examined precision cardiology in terms of machine-learning-based applications, combined statistical and mechanistic modelling techniques, clinical acceptability, translation, potential benefits, and limitations. In terms of scale, the digital twin elements were mostly applied at the organ level, modelled using one or more structural, biomechanical, and electrical characteristics of the heart derived from echocardiographic, tomographic, magnetic resonance and other imaging; also, electrocardiogram (ECG) databases and mathematical models. Two twin models using ‘human’ characteristics at the scale of a virtual patient incorporated descriptive data from health records and prospective biometric and behavioural data from smart wearables or other devices. One of the studies25 created a databank of profiles from existing electronic health records to derive multiple demographic and clinical variables against which to test antihypertensive treatment selection for patients. Using edge computing innovations in the context of ischaemic heart disease, another study26 used both an ECG database to train and test the AI dataset and smartphones paired with other external sensor devices, known as a body area network. Bluetooth connectivity and 5G network services communicated biometric data from the real twin’s smartphone to the digital twin in which the data fusion and analyses occurred.

Concepts in a digital twin model of the heart50.
CVD digital twin: industry participants
Recognising the expanding number of companies with a commercial interest in this fast-moving field, Supplementary Table 2 contains a listing that is illustrative of some of the available health digital twin or simulation modelling products for managing cardiovascular conditions, such as IHD, heart failure, and aneurysm repair. These products are mostly two- and three-dimensional computational models and software to assist device placement and haemodynamic modelling, rather than the definitive continuous bidirectional data exchange system of the physical and digital twin pair. The patent search identified 18 applications from 11 applicants, of which 73% were companies and 27% were universities. Three applicants had cardiac-related inventions and one of these was an author of an included paper27.
Health digital twin feasibility and implementation
Within the included papers, important shared translation issues for health digital twin research were illustrated by seven related themes (Fig. 4).

Translation issues in digital twin science.
Big data hazards
Methodological hazards were a noted challenge to using AI for inductive reasoning; for example, the generalisability of findings necessitates external validation with new patient cohorts, or cohorts from different centres or different geographical locations, and across time28. Other risks could be confounding biases, perhaps whereby a variable in the vast data suggests a spurious association. Selection biases could affect conclusions or result in models that exacerbate racial or other societal biases and could be overcome by weighting, for example. Overall, big data compels transparency, the plausibility of computer-generated predictions, and external validation28.
Computational power needs
The Internet of Things as applied to healthcare presents challenges for devices with processor, memory and energy limitations. Computational power and the costs of related infrastructure that supports the acquisition, storage and processing of data are fundamental for big data sets. Scalability requirements for compatibility with shared networks are compounded by cybersecurity risks29.
Data sharing and intellectual property issues
Databank development and data sharing within and between countries compels compliance with data protection requirements around consent, anonymizing data, data breach notifications and safe international transfer. National and international data privacy laws safeguard individual health information but demand vigilance against both inadvertent and malicious breaches. The outputs of big data processing and machine learning raise considerations for personal, institutional and commercial intellectual property30.
Cybersecurity
Transformational technologies present demands on a medical CPS or digital twin software for confidentiality, reliability, safety, and secure coding, with minimal requirements for patching. Cloud computing systems are, like more conventional physical media, subject to vulnerabilities in computational, storage, and infrastructure resources. Third-party-related risks include eavesdropping, malware, and costly denial-of-service attacks29. As long as commercial entities have an interest in personal and medical data collection, storage, and analysis, research that requires data harvesting attracts understandable public aversity to big data use, misuse, breaches and theft that must be mitigated31.
Professional barriers
The credibility of virtual patient models to predict disease risk and progression in a real patient, and the trust required of the computational processes that deliver these, presents a potential barrier to their uptake into a routine workflow. Further, despite the centrality of patient care to the role of a physician, fear of replacement or de-skilling of the clinician specialist with software and other technology has been mooted as an obstruction to translation32 to be balanced against the promise of greater efficiency and individualisation16. Alongside the technology-related reservations are concerns that AI applications might jeopardise the important social interactions between colleagues and between clinicians and patients, affecting the central experience of both groups in medicine32.
Ethical barriers
Creating a digital twin of a patient for precision medicine raises considerable ethical questions around its legacy, privacy, and identity; and its termination when the real twin dies. Practices around informed consent must adapt to allow access to the electronic medical records of a large population, for example, to develop a databank representative of that population and to release it for research purposes. Questions of equity concern who has access to the benefits derived from people’s biological data. Unknown is whether health digital twin creation exacerbates racial or other societal biases or discriminates against the least well off in society, or against populations under-represented in model cohorts that lack demographic and ethnic heterogeneity13. Who misses out? Individuals already differ in strength, health, and longevity—if these differences are quantified in a person’s digital twin, and made available to the entire community will new issues around discrimination or equality emerge33,34?
Governance and regulatory
All potential regulatory and legal issues for a health digital twin are as yet uncertain but are likely to be especially demanding for approval of devices associated with medical cyber-physical systems that contain large amounts of embedded software for sensing and monitoring people’s activities. The complexity and interconnectedness of such devices may drive changes to how verification, scalability and evidence are documented and submitted. The sophistication of databases that need to be collated, curated and expanded to enable an active digital twin for routine clinical decision-making may limit submissions to regulators to more passive-type models that use twinning concepts. Although the approval process of regulatory bodies may differ in purpose, cost, timeline, and perceived rigour between countries or regions35, products that use personalised computational modelling and simulation for procedure planning purposes are currently available in the market (see Supplementary Table 2 for examples of products marketed for use in structural heart disease, cardiac catheterisation, and aneurysm repair).
As this science becomes more visible in the marketplace the requirements for certification and approval may drive changes to the traditional processes used by national regulatory agencies. For example, in aiming to accelerate and streamline the product development process for device manufacturers, the United States Food and Drug Administration recently commenced a programme of pre-qualifying appropriate evaluation tools (such as a digital tool or a computer model) for later use in the actual regulatory submission stage (https://www.fda.gov/medical-devices/science-and-research-medical-devices/medical-device-development-tools-mddt). This aligns with recognition within its strategic priorities of both the growing area of simulation software as a medical device and the potential for computational modelling and AI tools to aid device evaluation and reduce costs in the overall regulatory pipeline36.
Governance mechanisms needed to safeguard the rights of persons with a digital twin could, for example, draw from existing practices for how medical databases and biobanks are designed, regulated, and inspected. Existing privacy safeguards may require strengthening when genomics data are expanded with biological and behavioural data29,33. Therefore, relevant legislation—timely and harmonised across jurisdictions—must develop and adapt in step with the adjustments made by other agencies responding to the repercussions of technological change in this field. Collaborations between academia, industry and government may benefit the standardisation of methods and interoperability of software and other protocols.
Discussion
This review explored the use of the term digital twin and its core concepts, chief of which is the notion of a continuous real-time multi-source data feed into the virtual twin, and the AI technologies that optimise these data into useful information about the physical twin. As intelligent systems that efficiently characterise, understand, cluster and classify complex data, health digital twins are proposed to augment, rather than displace, human intelligence in diagnostic and prognostic decisions in disease8. Estimating and stratifying risks, forecasting progression, choosing an intervention, and predicting its outcome using data streamed and integrated from many sources capture the role for digital twins in realising the possibilities of precision medicine. Importantly, the interplay of inductive and deductive reasoning underpins these operations within the cardiovascular digital twin model.
For CVD management, the potential for AI systems to more accurately phenotype patients with the same presentation or condition and overcome limitations of current risk-stratification algorithms could enable therapy selection that is based less on the responses of an average person than on the responses predicted in an individualised model33. Predictions about the best treatment for an individual would shift from being based on their current or past condition to being evaluated in the light of a future-facing simulation37. However, being able to collect and integrate in real time the multiple changeable molecular, physiological, behavioural, and other attributes of an actual person into a twin, then extract precise data for an intelligent digital representation is complex, and many obstacles to translation must be resolved. Among these challenges are computational power needs, cybersecurity concerns, data sharing issues, myriad ethical constraints, and barriers to adoption by clinicians of disease management decision tools derived from artificial intelligence systems.
Importantly, the characterisation of an active health digital twin as elucidated in this review is recent, relative to established complex modelling science used to make treatment predictions and inferences in disease, including CVD38,39. Use of the term digital twin in mechanistic models may be restrained by the absence of the definitive bidirectional data flow with a real patient, due to the extreme complexity required of a model to realistically be able to make such a claim. For example, the iterative process by which imaging data and engineering sciences combine towards an archetypal digital twin for clinical translation (figure in Box 2) underscores that clean separation between numerical modelling applications and the data-driven twin concept as identified in this review may be unrealistic. More compelling is the suggestion that synergistic mathematical (deductive) and data-driven (inductive) modelling could overcome limitations within, and build the links between, the information derived from each approach13,40. For example, within the digital twin construct and validation centred on a population-based databank, complementary deductive and inductive data modelling processes are at play13. The deductive, mechanistic model integrates clinical and experimental data to identify mechanisms and predict outcomes based on anatomical and mechanical knowledge of a physical system and hypothesised relationships13. Furthermore, such extensive system knowledge presents a descriptive advantage over an inductive or empirical model, and avoids the need to re-train a predictive mechanistic model for unseen data or new situations41. The advantages for clinical interpretability of such simulations may be constrained by the assumptions that are applied13, including the choice and impact of boundary conditions (Box 1) for measurements required to solve equations42. In contrast, the inductive, statistical pathway trains, tests, and revises complex data using machine-learning processes. It finds predictive relations, patterns and correlations when mechanisms are poorly understood, too complex to model mechanistically, or when missing data must be inferred13. An advantage of such empirically derived models is the capacity to efficiently process numerous multivariable data from, for example, biologic databases, wearable sensors, and other external sources8. Constraints may relate to the available volume and heterogeneity of data variables with which to train machine-learning systems13, and lower generalisation compared with mechanistic or physics-based models43. Furthering digital twin science will therefore likely continue to harness both data-driven and knowledge-based mathematical modelling. At the scale of the heart, for example, the feasibility of inductive-deductive model synergy for predicting conduction abnormalities has been reported from a retrospective study of aortic valve recipients44. In particular, use of machine learning to classify anatomical, procedural and mechanistic data augmented more traditional device-anatomy simulations to expand and integrate the available variables for reliably predicting new onset of bundle branch block or permanent pacemaker placement44. Acknowledgement of the achievements to date and substantial future challenges to integrate multiple physiological body systems is described in the widely-cited international initiative, the Virtual Physiological Human (https://www.vph-institute.org/projects.html).
This review concurs with other observations that digital twin research applications comprise elements, rather than all components, of the archetypal synchronised cyber-physical system supported by IoT connectivity13. Consequently, comparison of research and implementation would be aided by greater consensus about the digital twin definition45. Another important priority is to focus research into intuitive accessible ways for non-technical end-users to interact with digital twin systems in their field45. Future innovations include refining the visualisation methods by which non-expert users of a mirrored, networked system interact with the AI-derived information about the physical twin45. Augmented reality45,46, multidimensional holographic projections10,29, and 3D avatars8 are available methods; however, standardisation between multiple potential digital twins in a system would facilitate both their seamless interaction in the network connecting the virtual and physical twins, and the participation of human non-experts of data science45. The industry sector is expected to drive the key advances in the technologies that enable digital twin systems, for example, big data analytics platforms that favour localised over centralised storage, and parallel over serial processing of structured and unstructured data43. Improving IoT technologies will include developments in communication infrastructure such as wider availability of 5G mobile and internet, lower-cost sensor devices and flexible cloud and edge computing environments to meet the storage and processing needs of these networked services43. Further challenges are to ensure the timely and accurate update and replication of data derived from complex components of a physical twin (such as a human organ) into the digital twin to avoid delaying critical intervention in the physical twin29. Multiple digital twins within a shared interaction (such as the human body) need to exchange and synchronise information, requiring advancements in application programming interfaces that optimise consistent and predictable software-to-software interoperability29,45. Important developments within physics-based modelling involve improved affordability and fidelity of computational hardware to enable the equations governing a physical system (e.g., how vessels deform or interact with turbulent blood flow) to be solved faster; to improve the quality of 3D visualisations; and to accelerate the availability of training data sets for machine-learning models that are needed to create the digital twin43.
In the evolution of model-based personalisation for decision support, at least two socio-technical considerations of how such innovations flow into practice are essential for the clinical end-user: first, the accuracy, reproducibility, and consistency of data; and second, that measurement uncertainty is introduced into the data assimilation within the model42. Model-based applications lacking details of the effects of uncertainties within the clinical data that underpin the model can make the so-called black-box nature of AI feel uncomfortable and unrelatable to clinicians42. Therefore, among the challenges surrounding adoption is to optimise transparency around the evidence supporting the development and validation of a digital twin solution to aid treatment decisions or prognostic conclusions47. The progressive integration of AI-enabled platforms into traditional approaches to patient care will likely require the collaborative expertise from technological, biomedical, and behavioural sciences to cultivate conditions for uptake and routine use48. As models are validated in terms of an initial concept, a crucial step is extending the model to a more general patient cohort, with less controlled physiological and demographic characteristics13. The challenge of accessing large populations and their detailed information requires the development of so-called mega cohorts—prospective digital health ‘data lakes’; and big data infrastructure (including the techniques characterised as data fusion [Box 1]) to phenotype volunteers enrolled in these initiatives and to optimise the use, re-use, and sharing of these data13,49. Several established databanks supply anonymised data to researchers worldwide (National Institutes of Health, www.allofus.nih.gov/; UK Biobank, www.ukbiobank.ac.uk).
Among the strengths of this review is that its mapping intent enabled use of internet-sourced material alongside at least six types of scholarly publications, thus giving a fuller picture of the variety of disease conditions where digital twin science is being applied, and of the academic and non-academic stakeholders within this multidisciplinary field. Within an exploratory review of the term digital twin, several limitations should be noted. In taking a pragmatic approach to isolate work termed a digital twin, the search process may have excluded relevant papers describing predictive models but without explicit use of the term. Thus, the extent of digital twins for CVD in the published literature may be understated. We used a systematic search strategy within a mapping style of review; future studies of the field could alternatively conduct a systematic review of a narrower question and a smaller pool of papers of more uniform study design. The methodology assessments within that type of review would produce other perspectives on the topic. Material obtained from electronic databases and websites represents information available on the search date, risking that the review under-represents all available information on a rapidly advancing subject. The use of only English language sources potentially under-recognises all relevant literature in the field. One author charted the information from the various sources, risking that screening decisions could have resulted differently with multiple reviewers. Further, the potential has been mooted for AI and digital twin technology to gather ‘intelligence’ from vast volumes of patient data for optimising the patient experience, care coordination, scheduling, and other service-oriented operations at healthcare facility level7,8, but was not reviewed. The included papers did not evaluate any hypothesised economic benefits of digital twins applied to CVD management and this is an important area of future study.
In conclusion, digital twin research for CVD overall encompasses proof-of-concept studies illustrating the use of the data-driven approaches that typify the goals of precision medicine. The promise of an active digital twin of either the human heart or the human organism for clinical decision-making remains futuristic. Its advancement holds feasibility and implementation challenges that are not unique to CVD, namely that although grounded in AI it hinges on many human factors: citizen populations willing to prospectively contribute biodata towards mega cohorts of patients; an adaptive, agile ethical and regulatory landscape; and multidisciplinary scientific expertise. Review of the health digital twin term, concepts, and uses offered important contextual insights to the field in general and for CVD in particular for the recent collaborative workshop of clinicians, (bio)engineers, data scientists, and others required to advance research pathways for CVD, hosted by the University of Sydney Cardiovascular Initiative.

Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The datasets supporting the conclusions of this article are included within the article and its additional files.
References
Joseph, P. et al. Reducing the global burden of cardiovascular disease, part 1. Circ. Res. 121, 677–694 (2017).
Figtree, G. A. et al. Mortality in STEMI patients without standard modifiable risk factors: a sex-disaggregated analysis of SWEDEHEART registry data. Lancet 397, 1085–1094 (2021).
Vernon, S. T. et al. Increasing proportion of ST elevation myocardial infarction patients with coronary atherosclerosis poorly explained by standard modifiable risk factors. Eur. J. Prev. Cardiol. 24, 1824–1830 (2017).
Collins, F. S. & Varmus, H. A new initiative on precision medicine. N. Engl. J. Med. 372, 793–795 (2015).
Tranvåg, E. J., Strand, R., Ottersen, T. & Norheim, O. F. Precision medicine and the principle of equal treatment: a conjoint analysis. BMC Med. Ethics 22, 55 (2021).
Krassowski, M., Das, V., Sahu, S. K. & Misra, B. B. State of the field in multi-omics research: from computational needs to data mining and sharing. Front. Genet. 11, 1598 (2020).
Thuemmler, C. & Bai, C. Health 4.0: application of industry 4.0 design principles in future asthma management. In Health 4.0: How Virtualization and Big Data are Revolutionizing Healthcare (eds Thuemmler, C. & Bai, C.) 23–37 (Springer Int Publishing, Cham, 2017).
Barricelli, B. R., Casiraghi, E. & Fogli, D. A survey on digital twin: definitions, characteristics, applications, and design implications. IEEE Access 7, 167653–167671 (2019).
Erol, T., Mendi, A. F. & Doğan, D. The digital twin revolution in healthcare. In 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT). 1–7 (IEEE, 2020).
Croatti, A., Gabellini, M., Montagna, S. & Ricci, A. On the integration of agents and digital twins in healthcare. J. Med. Syst. 44, 161 (2020).
Lareyre, F., Adam, C., Carrier, M. & Raffort, J. Using digital twins for precision medicine in vascular surgery. Ann. Vasc. Surg. 67, e577–e578 (2020).
Tao, F., Zhang, H., Liu, A. & Nee, A. Y. C. Digital twin in industry: state-of-the-art. IEEE Transact. Industrial Inform. 15, 2405–2415 (2019).
Corral-Acero, J. et al. The ‘digital twin’ to enable the vision of precision cardiology. Eur. Heart J. 41, 4556–4564 (2020).
Peters, M. D. et al. Guidance for conducting systematic scoping reviews. In. J. Evid. Based Health 13, 141–146 (2015).
Arksey, H. & O’Malley, L. Scoping studies: towards a methodological framework. Int. J. Soc. Res. Method 8, 19–32 (2005).
Bhattad, P. B. & Jain, V. Artificial intelligence in modern medicine—the evolving necessity of the present and role in transforming the future of medical care. Cureus 12, e8041–e8041 (2020).
Dilsizian, M. E. & Siegel, E. L. Machine meets biology: a primer on artificial intelligence in cardiology and cardiac imaging. Curr. Cardiol. Rep. 20, 139 (2018).
Ahmadi-Assalemi, G. et al. Digital twins for precision healthcare. In Cyber Defence in the Age of AI, Smart Societies and Augmented Humanity (eds Jahankhani, H. et al.) 133–158 (Springer Int Publishing, Cham, 2020).
Chakshu, N. K., Sazonov, I. & Nithiarasu, P. Towards enabling a cardiovascular digital twin for human systemic circulation using inverse analysis. Biomech. Model Mechanobiol. 20, 449–465 (2020).
Petrova-Antonova, D., Spasov, I., Krasteva, I., Manova, I. & Ilieva, S. A digital twin platform for diagnostics and rehabilitation of multiple sclerosis. In Computational Science and Its Applications—ICCSA 2020 (eds Gervasi, O. et al.) 503–518 (Springer International Publishing, Cham, 2020).
Lal, A., Pinevich, Y., Gajic, O., Herasevich, V. & Pickering, B. Artificial intelligence and computer simulation models in critical illness. World J. Crit. Care Med. 9, 13–19 (2020).
Ravì, D. et al. Deep learning for health informatics. IEEE J. Biomed. Health Inform. 21, 4–21 (2017).
Naplekov, I. et al. Methods of computational modeling of coronary heart vessels for its digital twin. MATEC Web Conf. 172, 01009 (2018).
Vukicevic, M., Vekilov, D. P., Grande-Allen, J. K. & Little, S. H. Patient-specific 3D valve modeling for structural intervention. Structural Heart 1, 236–248 (2017).
Semakova, A. & Zvartau, N. Data-driven identification of hypertensive patient profiles for patient population simulation. Procedia Comput. Sci. 136, 433–442 (2018).
Martinez-Velazquez, R., Gamez, R. & El Saddik, A. Cardio twin: a digital twin of the human heart running on the edge. In 2019 IEEE International Symposium on Medical Measurements and Applications (MeMeA) 1–6 (IEEE, 2019).
Mazumder, O., Roy, D., Bhattacharya, S., Sinha, A. & Pal, A. Synthetic PPG generation from haemodynamic model with baroreflex autoregulation: a digital twin of cardiovascular system. In 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). 5024–5029 (IEEE, 2019).
Lamata, P. Avoiding big data pitfalls. Heart Metab 82, 33–35 (2020).
Jimenez, J. I., Jahankhani, H., & Kendzierskyj, S. Health care in the cyberspace: medical cyber-physical system and digital twin challenges. In Digital Twin Technologies And Smart Cities. Internet Of Things (Technology, Communications And Computing) (eds Daneshkhah, A. et al.) 79–92 (Springer Nature Switzerland, 2020).
Rivera, L. F. et al. Towards continuous monitoring in personalized healthcare through digital twins. In CASCON 2019: 29th Annual International Conference on Computer Science and Software Engineering, Ontario, Canada (eds Pakfetrat, T., Jourdan, G. V., Kontogiannis, K. & Enenkel, R.) 329–335 (IBM Corp., 2019).
Kendzierskyj, S., Jahankhani, H., Jamal, A. & Jimenez, J. I. The transparency of big data, data harvesting and digital twins. In Blockchain and Clinical Trial: Securing Patient Data (eds Jahankhani, H. et al.) 139–148 (Springer International Publishing, Cham, 2019).
Verghese, A., Shah, N. H. & Harrington, R. A. What this computer needs is a physician: humanism and artificial intelligence. J. Am. Med. Assoc. 319, 19–20 (2018).
Bruynseels, K., Santoni de Sio, F. & van den Hoven, J. Digital twins in health care: ethical implications of an emerging engineering paradigm. Front. Genetics 9, 31 (2018).
de Boer, B. Experiencing objectified health: turning the body into an object of attention. Med. Health Care Philos. 23, 401–411 (2020).
Landeen, K. C., Langerman, A. & Maldonado, F. An oversight in oversight: reconciling the medical device industry, clinicians, and regulation. CHEST 161, 300–330 (2022).
Morrison, T. M., Pathmanathan, P., Adwan, M. & Margerrison, E. Advancing regulatory science with computational modeling for medical devices at the FDA’s office of science and engineering laboratories. Front. Med. 5, 241–241 (2018).
Niederer, S. A. et al. Creation and application of virtual patient cohorts of heart models. Philos. Trans. A Math Phys. Eng. Sci. 378, 20190558 (2020).
Corsini, C., Migliavacca, F., Hsia, T.-Y. & Pennati, G. The influence of systemic-to-pulmonary arterial shunts and peripheral vasculatures in univentricular circulations: focus on coronary perfusion and aortic arch hemodynamics through computational multi-domain modeling. J. Biomech. 79, 97–104 (2018).
Stevens, M. C., Callaghan, F. M., Forrest, P., Bannon, P. G. & Grieve, S. M. A computational framework for adjusting flow during peripheral extracorporeal membrane oxygenation to reduce differential hypoxia. J. Biomech. 79, 39–44 (2018).
Lamata, P. Teaching cardiovascular medicine to machines. Cardiovasc. Res. 114, e62–e64 (2018).
Davies, M. R. et al. Recent developments in using mechanistic cardiac modelling for drug safety evaluation. Drug Discov. Today 21, 924–938 (2016).
Hose, D. R. et al. Cardiovascular models for personalised medicine: where now and where next? Med. Eng. Phys. 72, 38–48 (2019).
Rasheed, A., San, O. & Kvamsdal, T. Digital twin: values, challenges and enablers from a modeling perspective. IEEE Access 8, 21980–22012 (2020).
Galli, V. et al. Towards patient-specific prediction of conduction abnormalities induced by transcatheter aortic valve implantation: a combined mechanistic modelling and machine learning approach. Eur. Heart J. Digit. Health 2, 606–615 (2021).
Liu, Y. K., Ong, S. K. & Nee, A. Y. C. State-of-the-art survey on digital twin implementations. Adv. Manufactur 10, 1–23 (2022).
Erol, T., Mendi, A. F. & Doğan, D. Digital transformation revolution with digital twin technology. In 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT) (ed İKI, L. R. & BOZUCU, E.). 1–7 (IEEE, 2020).
Davenport, T. & Kalakota, R. The potential for artificial intelligence in healthcare. Future Healthc. J. 6, 94–98 (2019).
Coorey, G., Figtree, G. A., Fletcher, D. F. & Redfern, J. The health digital twin: advancing precision cardiovascular medicine. Nat Rev Cardiol 18, 803–804 (2021).
Fagherazzi, G. Deep digital phenotyping and digital twins for precision health: time to dig deeper. J. Med. Internet Res. 22, e16770 (2020).
Bende, A. & Gochhait, S. Leveraging digital twin technology in the healthcare industry—a machine learning based approach. Eur. J. Molec. Clin. Med. 7, 2547–2557 (2020).
Auricchio, F. et al. Patient-specific aortic endografting simulation: from diagnosis to prediction. Comput. Biol. Med. 43, 386–394 (2013).
Biancolini, M. E., Capellini, K., Costa, E., Groth, C. & Celi, S. Fast interactive CFD evaluation of hemodynamics assisted by RBF mesh morphing and reduced order models: the case of aTAA modelling. Int. J. Interactive Design. and Manufacturing (IJIDeM) 14, 1227–1238 (2020).
Hemmler, A., Lutz, B., Kalender, G., Reeps, C. & Gee, M. W. Patient-specific in silico endovascular repair of abdominal aortic aneurysms: application and validation. Biomech. Model Mechanobiol. 18, 983–1004 (2019).
Larrabide, I. et al. Fast virtual deployment of self-expandable stents: method and in vitro evaluation for intracranial aneurysmal stenting. Med. Image Anal. 16, 721–730 (2012).
Wagner, P. et al. PTB-XL, a large publicly available electrocardiography dataset. Sci. Data 7, 154–154 (2020).
Saeed, M. et al. Multiparameter Intelligent Monitoring in Intensive Care II: a public-access intensive care unit database. Crit. Care Med. 39, 952–960 (2011).
Chakshu, N. K., Carson, J., Sazonov, I. & Nithiarasu, P. A semi-active human digital twin model for detecting severity of carotid stenoses from head vibration: a coupled computational mechanics and computer vision method. Int. J. Numer Method. Biomed. Eng. 35, e3180 (2019).
Jones, G. et al. Machine learning for detection of stenoses and aneurysms: application in a physiologically realistic virtual patient database. Biomech. Model. Mechanobiol. 20, 2097–2146 (2021).
Jones, G. et al. A physiologically realistic virtual patient database for the study of arterial haemodynamics [Data set]. Int. J. Numer Method Biomed. Eng. https://doi.org/10.5281/zenodo.4549764 (2021).
Sharma, P., Suehling, M., Flohr, T. & Comaniciu, D. Artificial Intelligence in diagnostic imaging: status quo, challenges, and future opportunities. J. Thorac Imag. 35, S11–S16 (2020).
Hirschvogel, M., Jagschies, L., Maier, A., Wildhirt, S. M. & Gee, M. W. An in silico twin for epicardial augmentation of the failing heart. Int. J. Numer Method Biomed. Eng. 35, e3233 (2019).
Pagani, S., Dede, L., Manzoni, A. & Quarteroni, A. Data integration for the numerical simulation of cardiac electrophysiology. Pacing. Clin. Electrophysiol. 44, 726–736 (2021).
Gillette, K. et al. A framework for the generation of digital twins of cardiac electrophysiology from clinical 12-leads ECGs. Med. Image Anal. 71, 102080 (2021).
Camps, J. et al. Inference of ventricular activation properties from non-invasive electrocardiography. Med. Image Anal. 73, 102143 (2021).
Gerach, T. et al. Electro-mechanical whole-heart digital twins: a fully coupled multi-physics approach. Mathematics 9, 1247 (2021).
Niederer, S. A., Lumens, J. & Trayanova, N. A. Computational models in cardiology. Nat. Rev. Cardiol. 16, 100–111 (2019).
Peirlinck, M. et al. Precision medicine in human heart modeling: perspectives, challenges, and opportunities. Biomech. Model Mechanobiol. 20, 803–831 (2021).
Acknowledgements
The authors thank the University of Sydney Cardiovascular Initiative and the following individuals: Dr. John O’Sullivan; Dr. Ryan P. Sullivan, Head of the Australian Imaging Service, School of Biomedical Engineering, University of Sydney. G.C. was supported by a Cardiovascular Initiative Ignite Award from the University of Sydney. G.A.F. is supported by a National Health and Medical Research Council Practitioner Fellowship [GNT1135920]. A.M. is supported by The Ainsworth Chair of Technology and Innovation, Cerebral Palsy Alliance Research Foundation. J.O. is supported by a National Heart Foundation of Australia Postdoctoral Fellowship [No. 104809]. J.R. is supported by a National Health and Medical Research Council Career Development Fellowship [APP1143538].
Author information
Authors and Affiliations
Contributions
G.F., V.S., D.F.F., J.R. and G.C. equally contributed to the conceptualisation, drafting, editing, and finalising of the manuscript. G.C. led the data acquisition and created the figures with assistance from D.F.F. and D.W. G.C., G.F., D.F.F., V.S., S.V., D.W., S.M.G., A.M., J.Y., P.Q., K.O., J.O., J.K., S.P. and J.R. made substantial contributions to the analysis or interpretation of the data; revised it critically for important intellectual content; and approved the completed version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Coorey, G., Figtree, G.A., Fletcher, D.F. et al. The health digital twin to tackle cardiovascular disease—a review of an emerging interdisciplinary field. npj Digit. Med. 5, 126 (2022). https://doi.org/10.1038/s41746-022-00640-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-022-00640-7
This article is cited by
-
Advancements and challenges of digital twins in industry
Nature Computational Science (2024)
-
A roadmap for the development of human body digital twins
Nature Reviews Electrical Engineering (2024)
-
Leveraging continuous glucose monitoring for personalized modeling of insulin-regulated glucose metabolism
Scientific Reports (2024)
-
Assessing the benefits of digital twins in neurosurgery: a systematic review
Neurosurgical Review (2024)
-
Data-driven quantification and intelligent decision-making in traditional Chinese medicine: a review
International Journal of Machine Learning and Cybernetics (2024)
